Réorganisation des LXC, panne du NUC, refonte du homelab : retour sur un mois mouvementé


Il y a des projets qu'on repousse pendant des mois. Pas parce qu'ils sont complexes, mais parce qu'ils ne sont pas urgents. L'infra tourne, les services fonctionnent, et remettre les mains dedans hors la maintenance habituelle, les mises à jour ou le déploiement d'un nouveau service, ça demande une bonne raison.
La mienne est venue d'un constat simple : mon conteneur LXC principal hébergeait un fatras de services Docker accumulés au fil du temps. Certains étaient essentiels, d'autres obsolètes, quelques-uns en doublon avec des outils que je documente et propose déjà sur DomoPi, comme SearXNG ou BentoPDF. Autant de bonnes raisons de faire le ménage.
Point de départ
L'infrastructure de base est simple. Un NUC Minisforum MS-01 comme serveur principal, équipé d'un processeur Intel Core i9, de plusieurs slots M.2 pour le stockage NVMe, et de 2 ports réseau 10 GbE. Une machine taillée pour des charges de travail sérieuses, et confortable pour un homelab en pleine croissance.
Le MS-01 tourne sous Proxmox. C'est lui qui héberge l'ensemble des conteneurs LXC et des VMs. En complément, un NAS Synology 8 baies assure le stockage des médias et les sauvegardes. Les deux machines forment le cœur de l'infra.
Côté organisation, trois conteneurs LXC étaient en place. Un premier, lxc-emby, dédié au serveur média avec passage de la carte graphique en passthrough pour le transcodage matériel. Un deuxième, lxc-download, regroupant les *arr et les outils de téléchargement. Et un troisième, lxc-docker, qui hébergeait tout le reste : une stack Docker Compose avec une trentaine de services, du reverse proxy à la domotique, en passant par le monitoring, les outils de productivité, et quelques services expérimentaux déployés un soir pour tester et jamais supprimés depuis.
C'est ce dernier qui posait problème. Ça fonctionnait, mais ça avait tous les défauts d'un monolithe. Une panne ou une mauvaise manipulation pouvait tout emporter. Les ressources n'étaient pas isolées : un service gourmand pénalisait les autres. La maintenance était opaque, difficile de savoir d'un coup d'œil ce qui tournait vraiment, pourquoi, et si c'était encore utile. Et certains services n'avaient carrément plus de raison d'être là : SearXNG, BentoPDF, des doublons maintenus pour rien.
Le problème avec ce type d’organisation, c’est qu’elle dérive facilement avec le temps. On ajoute un service, puis un autre, puis un troisième, jusqu’au moment où l’ensemble devient difficile à lire, à maintenir, et qu’on hésite à y toucher de peur de casser quelque chose. C’était exactement le cas ici et le signe qu'il est temps de remettre de l'ordre.
Remettre de l'ordre : séparer les responsabilités
L'idée n'est pas de tout réinventer. Juste d'appliquer un principe simple : un LXC pour une responsabilité fonctionnelle.
Ce découpage répond à plusieurs objectifs concrets. L'isolation d'abord : si un conteneur rencontre un problème, les autres ne sont pas affectés. La lisibilité ensuite : en ouvrant Proxmox, on doit comprendre immédiatement ce qui tourne où. Le nom du conteneur ou de la VM suffit, pas besoin de se connecter dessus pour savoir ce qu'il héberge. La maintenabilité enfin : mettre à jour les services d'un domaine sans toucher aux autres, allouer les ressources de façon ciblée, supprimer ce qui ne sert plus sans risquer de casser quelque chose d'adjacent. Docker isole déjà bien les services entre eux, mais séparer aussi les rôles au niveau des LXC apporte un gain supplémentaire en lisibilité, en maintenance et en contrôle des ressources.
Le critère de regroupement n'est pas arbitraire. Pour chaque LXC, la question posée est pragmatique : est-ce que ces services ont les mêmes besoins en termes de ressources, de fréquence de mise à jour, de criticité, et de relations entre eux ? Des services qui communiquent beaucoup entre eux ont intérêt à cohabiter. Des services critiques qui ne doivent jamais tomber n'ont pas à partager leur espace avec des applications qu'on met à jour régulièrement et qui peuvent redémarrer sans impact. Des services gourmands en I/O méritent leur propre conteneur pour ne pas pénaliser le reste.
Séparer les LXC ouvre aussi des possibilités qu’un conteneur unique ne permet pas vraiment. On peut choisir la distribution la plus adaptée selon l’usage, bloquer une mise à jour sur un LXC sans impacter les autres, ajuster finement les ressources et les permissions, ou encore attribuer facilement une IP dédiée à certains services quand c’est nécessaire.
Le nouveau découpage
Voici l'architecture retenue, avec 6 conteneurs LXC aux responsabilités clairement délimitées.
lxc-network regroupe AdGuard Home, utilisé principalement comme bloqueur de publicités et DNS interne, et NPM en reverse proxy. Ces 2 services sont fonctionnellement liés, ont les mêmes exigences de disponibilité et le même profil de maintenance. Les séparer n'aurait apporté aucun bénéfice réel.
lxc-infra regroupe le socle opérationnel : Vaultwarden, Beszel, Dockhand, NexTerm et les outils de backup. Ce sont les outils qui servent à gérer le homelab lui-même. Ils doivent tourner en permanence, indépendamment de tout le reste. Si lxc-apps est en rade, lxc-infra doit rester accessible pour pouvoir intervenir.
lxc-domotique regroupe Home Assistant, Zigbee2MQTT et Homebridge. Ces trois services sont très interdépendants et forment une brique qu'on gère globalement. C'est une partie critique de l'infra au quotidien et on y touche le moins possible.
lxc-apps regroupe les applications du quotidien : N8N pour l'automatisation, Rallly pour la planification, Spoolnymous pour la gestion complète de l'atelier impression 3D, et d'autres services en test. Ces services évoluent fréquemment et ne sont pas critiques.
lxc-emby reste dans son propre LXC dédié pour conserver le passthrough de la carte graphique et assurer le transcodage matériel.
lxc-media (renommé depuis lxc-download) prend en charge la stack médias et téléchargements : Jellyseerr, Sonarr, Radarr, Prowlarr, Transmission et NZBGet. Ces services sont intensifs en I/O et ont des besoins en ressources spécifiques. Les outils de téléchargement utilisent des réseaux Docker en macvlan pour obtenir leur propre adresse IP, ce qui permet d'appliquer une règle firewall UniFi pour forcer leur trafic via le VPN.
La migration en pratique
Début mars, une matinée est bloquée pour tout migrer. La première étape avant de déplacer quoi que ce soit : créer les nouveaux conteneurs LXC dans Proxmox. Pour chacun, on configure les ressources CPU et RAM, le stockage, le réseau. Ça prend une heure. Ensuite seulement, on commence à migrer les services un par un, en les regroupant par LXC, en commençant par les moins critiques.
La procédure est toujours la même : arrêt de la stack, archivage, transfert, restauration, relance, ajustement du reverse proxy et vérification. Hexamus a d’ailleurs publié un article dédié sur la migration d’un conteneur Docker entre deux hôtes Linux, qui détaille tout ça pas à pas :

Pour chaque service, 3 questions se posent : est-ce que j'en ai vraiment besoin ? Est-ce que je l'utilise régulièrement ? Est-ce qu'il n'est pas déjà couvert autrement ? Une bonne dizaine de services ont été supprimés au passage, sans regret. Autant de conteneurs en moins à maintenir, autant de RAM récupérée.
Au total, création des LXC, déplacement des services, tests et nettoyage de l'ancien conteneur : quelques heures en tout. Pas de casse, pas de service perdu. Une de ces opérations qu'on redoute plus qu'elle ne le mérite.
Tout allait bien jusqu'à la panne...
Un matin, réveil sans internet. L'onduleur sur lequel reposaient la box Free, le routeur UniFi (et sa borne WiFi PoE) et le MS-01 s'est arrêté dans la nuit, sans raison apparente, sans coupure de courant détectée. Lui seul. Mystère complet.
Quand l'onduleur est rallumé, tout redémarre normalement : la box, le routeur, la borne WiFi. Tout sauf le MS-01. Je dois partir au boulot, mais pas question de laisser madame sans internet pour la journée. Première priorité : rétablir la connectivité rapidement. La config DNS dans UniFi est modifiée pour pointer vers un DNS public, ce qui suffit à rendre la connexion opérationnelle sans passer par AdGuard Home qui tournait sur le MS-01. Affaire réglée en quelques minutes.
Ensuite commencent les investigations. Pas d'image, pas de bip, pas de ventilateur qui démarre... ça sent mauvais. Reset CMOS en retirant la pile bouton pendant 30 secondes : rien. Le bloc d'alimentation est testé et fonctionne bien, ce n'est donc pas lui le coupable. Il resterait à tester la mémoire barrette par barrette et éventuellement à court-circuiter les pins power directement sur la carte mère pour éliminer un bouton défectueux, mais le diagnostic est quand même assez évident : la carte mère est hors service.

C'est frustrant. La machine venait de traverser une migration propre, tout tournait bien. Je ne sais pas vraiment ce qui s'est passé cette nuit-là, l'onduleur a peut-être subi une surtension, peut-être pas. Difficile à dire. Ce qui est sûr, c'est que la carte mère n'a pas survécu.
Le MS-01 est sous garantie, mais le vendeur est un tiers sur Amazon et je n'avais pas envie de gérer un dossier SAV en ce moment. La politique de retour Amazon fait le travail : remboursement intégral et sans négociation.
L'infra ne peut pas rester à l'arrêt pour autant, il faut une solution rapide. Puisqu’il fallait remplacer rapidement la machine, autant en profiter pour corriger aussi le principal défaut de l’infra précédente : sa dépendance à un serveur unique.
Les critères pour le remplaçant sont clairs : livraison rapide, compatibilité Proxmox, mémoire DDR5, NVMe M.2 pour réutiliser les SSD du MS-01, 16 Go de RAM minimum, et au moins du 2,5 GbE.
Le 10 GbE du MS-01, c'était un confort appréciable, mais clairement surdimensionné pour un homelab. Y renoncer n'est pas rédhibitoire, et ça ouvre le choix à beaucoup plus de machines.
Le choix se porte sur l'ACEMAGIC M1, équipé d'un AMD Ryzen 6800H et de 16 Go de RAM, j'en commande donc 2. Bon rapport performances/prix, disponible immédiatement, et compatible Proxmox. La mémoire est en LPDDR5 soudée, ce qui pourrait être un frein, mais avec 2 machines et la possibilité d'en ajouter d'autres plus tard si besoin, ce n'est pas un problème.

ACEMAGIC M1
Processeur AMD Ryzen 7 6800H (8C/16T, jusqu'à 4,7 GHz)
Mémoire 16Go LPDDR5
SSD M.2 512Go
Vers une infrastructure plus résiliente
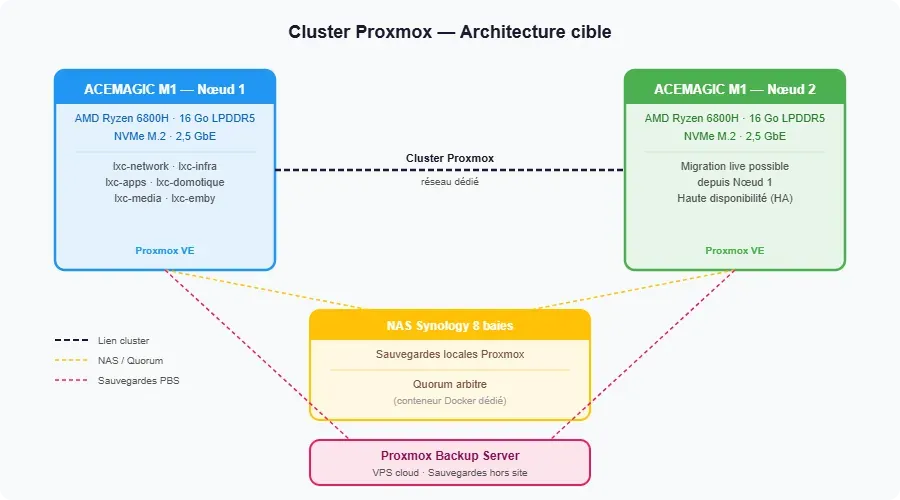
Ça faisait un moment que je voulais explorer le cluster Proxmox, sans jamais trouver le temps de m'y mettre. Avec 2 ACEMAGIC M1 qui arrivent, c'est l'occasion de se lancer et d'en profiter pour documenter comme il faut : l'infrastructure, l'architecture, les VMs et LXC, les services Docker, la façon dont c'est installé et configuré. Un inventaire complet de ce qui tourne, qui manquait jusqu'ici.
Un cluster Proxmox, c'est plusieurs serveurs qui fonctionnent ensemble et se voient comme un ensemble cohérent depuis une interface unique. On gère les VMs et LXC sur l'ensemble des machines depuis un seul endroit, on peut déplacer des VMs et LXC d’un serveur à l’autre bien plus facilement, ce qui apporte une vraie souplesse d’exploitation. C'est aussi ce qui permet d'activer la haute disponibilité : si un serveur tombe, Proxmox redémarre automatiquement les services critiques sur l'autre. Et avec 2 machines de 16 Go de RAM, c'est 32 Go de ressources disponibles pour l'ensemble de l'infra, répartis selon les besoins.
Le seul point technique à gérer : le quorum. Avec 2 serveurs, si l'un tombe, l'autre ne sait pas s'il peut continuer seul ou si les deux sont encore actifs quelque part sur le réseau mais n'arrivent juste pas à communiquer ensemble. Pour trancher, Proxmox a besoin d'un troisième élément qui fait office d'arbitre. Ici, ce sera un simple conteneur Docker sur le Synology, pas besoin d'une machine dédiée pour ça.
Pour les sauvegardes, les LXC et VMs sont déjà sauvegardés directement depuis Proxmox vers le Synology. Ça couvre déjà les erreurs de manipulation ou la panne d’un hôte, comme on vient de le vivre. En revanche, ça ne protège pas d’un problème touchant le NAS lui-même, d’où l’intérêt d’externaliser aussi une copie. PBS va permettre d'avoir 2 destinations de sauvegarde configurées dans Proxmox : le Synology en local pour la rapidité de restauration, et un VPS dans le cloud pour externaliser. PBS apporte aussi la déduplication et la compression des sauvegardes, ce qui réduit significativement l’espace utilisé tout en permettant d’en vérifier l’intégrité à tout moment.
Bilan
En quelques semaines, l'infra a connu plus de changements qu'en toute une année. Une migration propre menée en quelques heures, une panne aussi bête qu'imprévisible, et au final une infrastructure bien plus robuste qu'avant.
Sans cet onduleur probablement défaillant, le passage en cluster aurait encore attendu. C'est une de ces situations où la contrainte force une décision qu'on repoussait sans réelle bonne raison.
Au passage, cette mésaventure m'a rappelé qu'un onduleur non monitoré, c'est une boîte noire. Hexamus avait publié un article sur l'intégration d'un UPS dans Proxmox via NUT, que je n'avais pas encore pris le temps de mettre en pratique. C'est désormais dans la liste des choses à mettre en place rapidement !

Bien entendu, la mise en place du cluster Proxmox avec les deux ACEMAGIC M1 et le quorum sur Synology, ainsi que la configuration de PBS feront l'objet d'articles dédiés.
Si vous avez des questions ou des retours, c'est en commentaire ou sur le groupe Telegram que ça se passe.